关于snort的中文文档也不少,先根据文档了解一下基本特征,然后就可以参考已有的规则进行学习了,这样比较快。
学习文档:网上多的是,需要注意的是,一定要安装对应版本snort指定版本的wincap程序。
当时下来这些来试的,版本不对是真报错啊。
安装
根据csdn的来就行,注意把里面的unix目录格式改成Windows格式;
我的工作内容就是利用snort进行流量包的匹配,所以这里config需要个性化修改一下。
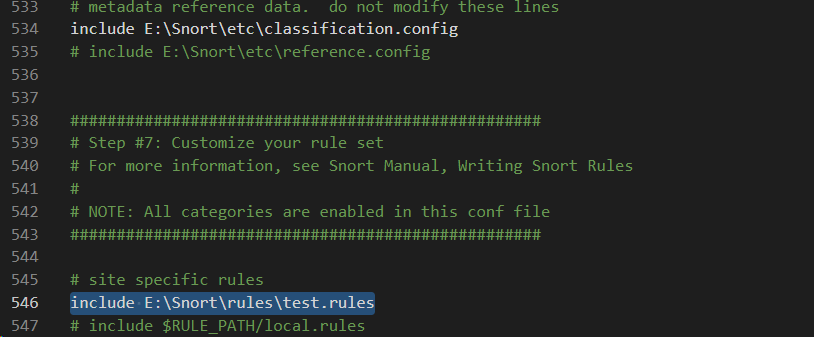
把其他的都注释掉,添加这一行,这里面存放的是我每一次写的规则。不知道为啥有几个字段会报错,直接不写就行了。
核心是content字段和msg字段,其他的都是锦上添花,sid不能重复,不然就会重叠规则,rev可以一样,无所谓。需要注意的是:
rev不同,sid也不能一样,这需要注意一下
每次把上一次的规则注释掉写新的就行了。
规则核心
msg字段,确定是什么家族或者组织。
content字段:要匹配的内容,核心中的核心
pcre字段:正则匹配,和content差不多。
比如:pcre:"/id=\d+&vs=\d+.\d+&sd=\w+&os=\d+&bi=\d+&ar=\d+&pc=\w+-PC&un=\w+&dm=&av=\d+&lv=\d+&og=\d+/"
还有一些固定的字段:
flow:established,to_client;这是代表向客户端发的流量
flow:established,to_server;这是向服务端发送的流量
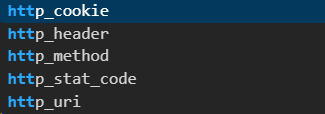
这些标签是真的有用,像host字段啥的都属于header
nocase关键字:屏蔽大小写
基本常用的就这些字段和标签。
自动化
自动转换
因为从沙箱上拉下来的流量包格式是cap,太老了,snort扫描不了,所以需要先转换一下,并且将名称规范化一下。
def tshark_command_run():
# 源目录和目标目录的路径
source_dir = '***************\\从pcap中提取'
target_dir = '***************\\hash_pcap'
# 获取源目录中所有的cap文件列表
cap_files = [f for f in os.listdir(source_dir) if f.endswith('.cap')]
# 遍历每个cap文件并进行转换
for cap_file in cap_files:
# 构建输入文件和输出文件的完整路径
input_file = os.path.join(source_dir, cap_file)
output_file = os.path.join(target_dir, cap_file.split("_")[3] + '.pcap')
command = "E:\\Wireshark\\tshark.exe -F pcap -r " + input_file + " -w " + output_file
# print(command)
res = os.system(command)
if (res == 2):
command = "copy " + input_file + " " + output_file
os.system(command)
print(f"sucess to copy {output_file}")
# time.sleep(0.5)
print(f"转换完成:{cap_file} -> {output_file}")
自动遍历
一共遍历了11000个pcap,写了一些半自动化的脚本来提高速度。
自动使用规则检查数据包的脚本
def IF_HitRule(log_path):
try:
ids_path = log_path+"\\"+"alert.ids"
if os.path.getsize(ids_path) != 0:
# 命中规则
return 1
else:
# 没有命中规则
return 0
except:
print(log_path)
return 0
def run_cmd_silently(cmd):
# 执行命令,并将标准输出、标准错误输出都重定向到空设备
subprocess.run(cmd, shell=True, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
def snort_command_run():
print("start scan pcap file")
# 源目录和目标目录的路径
source_dir = '************\\hash_pcap'
# 获取源目录中所有的cap文件列表
cap_files = [f for f in os.listdir(source_dir) if f.endswith('.pcap') or f.endswith('.pcapng')]
# 遍历每个cap文件
for cap_file in tqdm(cap_files):
log_path = source_dir+"\\log\\"+cap_file
# print(log_path)
os.system("mkdir "+log_path)
command = "snort -c E:\\Snort\\etc\\snort.conf -l "+log_path+" -r "+cap_file
# print(command)
# run_cmd_silently(command)
os.system(command)
time.sleep(1)
res = IF_HitRule(log_path)
if res == 1:
# os.remove(cap_file)
os.rename(cap_file, "OLD4_"+cap_file)
并且将命中的pcap包改名,就得到了msg_hash.pcap的流量包。
如何判断命中呢?
def IF_HitRule(log_path):
try:
ids_path = log_path+"\\"+"alert.ids"
if os.path.getsize(ids_path) != 0:
# 命中规则
return 1
else:
# 没有命中规则
return 0
except:
print(log_path)
return 0
检查生成的ids文件是否有内容,如果有内容就说明命中了。
生成对应关系
领导要求要规则和hash数据包对应,所以写了这个脚本。
def mkrule_txt():
source_dir = '*********\\sorted\\'
# 获取源目录中所有的cap文件列表
cap_files = [f for f in os.listdir(source_dir) if f.endswith('.pcap') or f.endswith('.pcapng')]
# 遍历每个cap文件
dict = {}
for cap_file in tqdm(cap_files):
tmp = cap_file.replace('jan1W', 'jan-W').replace("320", "32.").replace("GMLtaNHaoMTB","GMLtaNHaoMTB_")
tmp = tmp.split('_')
try:
msg = tmp[0]
hash = tmp[1]
except:
print(cap_file)
continue
if msg not in dict:
dict[msg] = []
dict[msg].append(hash)
print(dict)
with open("pcap_rules.txt", "w")as file:
file.write(json.dumps(dict, ensure_ascii=False, indent=3))
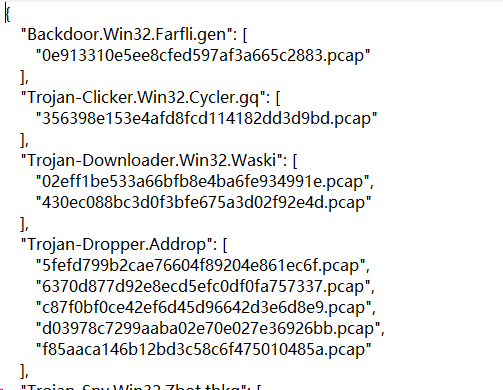
生成的txt文件长这样,我觉得这么对应起来也挺麻烦,但是领导说行,行就行呗。
总结
我学了yara规则和sigma规则,但是工作内容是snort规则,这倒好,我三大规则都学完了。
现在经济形式不好,企业都在想着办法的挣钱,之前的研发部门现在也要为一线产品赋能了,隔壁组也在为产品提供规则。